3 - Sub-Queries and Set Operators
Table of Contents
- Type of Queries
- Review of Views
- Sub-Queries
- Venn Diagrams
- Set Operators
Types of Query Results
In order to understand when and why you might use sub-queries, it is important to first understand the results that we get from non nested queries. All queries produce a table of data, regardless of the number of columns or rows that are returned; the results is still a table. However, looking closer we can determine that not all tables are the same and that tables that look one way might actually not be what they appear to be.
So query results can generally be divided into 3 hierarchical categories.
- Table - any data set that has at least one column, number of rows is irrelevant.
- List - a result set that contains exactly one column, number of rows is irrelevant
- Scalar - a result that is guaranteed to only ever have one column and one row.
It is sometimes misleading when you get a result that gives a single value (1 column and 1 row) but it cannot be considered a scalar, because if in the future the data changes and you could get more than one row, than it cannot be a scalar, but is a list.
Note that scalars are also lists and tables, lists are tables, but not scalars, and tables are tables, but not lists or scalars.
Examples
All of the following SELECT statements will produce tables, but cannot be classified as lists or scalars.
Tables
SELECT * FROM employees;
SELECT firstname, lastname
FROM employees;
SELECT employeeID, firstName, lastName
FROM employees
WHERE lower(lastname) LIKE 'jones' AND lower(firstname) LIKE 'andrew';
The third example above has multiple columns and looks like it would return a single row, but could have multiple rows as well.
Lists
SELECT employeeID FROM employees;
SELECT lastname FROM employees;
SELECT employeeID
FROM employees
WHERE lower(lastname) LIKE 'jones' AND lower(firstname) LIKE 'andrew';
The third example above can sometimes be confusing because we are obviously intending to find a single person and return their one employeeID, but there is no guarantee that there is not more than one 'Andrew Jones' working for the company, and therefore it is possible to get more than one row returned, and thus it can not be considered a scalar.
Scalar
SELECT count(employeeID) FROM employees;
SELECT max(orderNumber)
FROM orders;
SELECT teamName
FROM teams
WHERE teamID = 12;
All three of the above queries can only ever return a single column and single row and therefore can be considered scalar queries.
Why is Query Type Important
The reason why we must consider the type of query is because we are about to embark on the implementation of sub-queries. Inside of SELECT statements, we can place alternative sources for the information by nesting queries or placing a sub-query inside another query. The type of query that can be placed will depend on where it will be placed.
Inserting a sub-query in the FROM clause will require a table (remembering that both lists and scalars are also tables).
Sub-queries can also be used within the WHERE clause can include lists and scalars.
- Placing a sub-query after an "=" will require a scalar query as the comparison operator requires a single value to be compared.
- Placing a sub-query within an IN() comparison operator will accept a list query, as the IN operator contains a comma separated list.
Examples
Let us learn through examples using the following table schema.

Example 1
List all the employees, by name, whom work in the city of Seattle! (Do not use JOINS)
We will start this solution by looking at the information we know (City = Seattle) and obtaining the location_id for that record or records
-- STEP 1 SELECT location_id FROM locations WHERE lower(city) = 'seattle'; -- let us say this query return the value of 1700 -- it must also be noted that although we only got 1 result, it is possible to get more than one, -- so this must be considered a list query and not a scalar Query
Now using this result of 1700 we can get the departments that are in that location or locations.
-- STEP 2 SELECT department_id FROM departments WHERE location_id IN (1700); -- note that we used IN rather than =, because the previous query may have produced more than one value -- we might get results like 10, 90, 110, 190
having returned a single column list of department_id's gives us then the opportunity to get the employee information whom work in those departments.
-- STEP 3 SELECT employee_id, first_name, last_name FROM employees WHERE department_id IN (10, 90, 1010, 1090); -- this should give us the list employees whom work in Seattle.
so although we now have the answer we were looking for, we have created 3 queries and hard coded values at more than one step. We should create queries that are more dynamic and allow us to use the same query for the results to many cities directly.
-- first we will replace 'Seattle' from Step 1 above with a parameter DECLARE @city varchar(20); SET @city = 'Seattle'; SELECT location_id FROM locations WHERE lower(city) LIKE '%' + TRIM(lower(@city)) + '%'; -- this allows us to find the location_ids from any city typed in by a user. -- Next we will take step 2 and replace the value 1700 with the query that got us that value, with the parameter SELECT department_id FROM departments WHERE location_id IN ( SELECT location_id FROM locations WHERE lower(city) LIKE '%' + TRIM(lower(@city)) + '%' ); -- Now we take step 3 and replace the hard coded values with the query above that would produce those values anyways SELECT employee_id, first_name, last_name FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location_id IN ( SELECT location_id FROM locations WHERE lower(city) LIKE '%' + TRIM(lower(@city)) + '%' ) );
This final query above will now let us get the employees from any city at any time as typed in by a parameter. Much more useful and reusable.
So far we have seen examples where the sub-query is nested within the WHERE clause. We can also use Tabular queries as the data source for queries as well.
Example 2
List all employees whom work in Seattle whose first name starts with an 'S'.
we will start where we ended with the last example!
SELECT employee_id, first_name, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id IN (
SELECT location_id
FROM locations
WHERE lower(city) LIKE '%' + TRIM(lower(@city)) + '%'
)
);
and then wrap those queries with a simple query!
SELECT *
FROM employees
WHERE upper(first_name) LIKE 'S%';
A simple statement that does not yet take into account employees in Seattle yet!
becomes ....
DECLARE @city varchar(20);
SET @city = 'Seattle';
SELECT *
FROM (
SELECT employee_id, first_name, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id IN (
SELECT location_id
FROM locations
WHERE lower(city) LIKE '%' + TRIM(lower(@city)) + '%'
)
)
)
WHERE upper(first_name) LIKE 'S%';
so sub-queries can be used as the course for a FROM clause as well. This is very similar to the use of a view, in fact sub-queries are used in conjunction with views very often to help assist in creating object oriented SQL code.
Example 3
List the employees, by name, and the department name from which they work, without using joins.
So to get information, that will be an output column, in the output without using joins, it is important to get information from multiple tables. We can utilize the fact that sub-queries can also be implemented in the SELECT clause in addition the the previous examples using the WHERE and FROM clauses.
SELECT
first_name,
last_name,
( SELECT department_name
FROM departments
WHERE department_id = e.department_id )
FROM employees e
ORDER BY last_name, first_name;
In the above solution, we can insert the employees department_id into the WHERE clause of the sub-query by using the e table alias.
If we also recall from order of execution, that the SELECT clause executes iteratively, as a loop, through each row of the result set. Therefore, the sub-query is run on each row of the employees table and thus we can get the specific department_id for each row.
Set Operators
It is often necessary to put two lists together that have similar columns, but very different queries and conditions to obtain. A quick example would be: list all people a company contacts, both employees and customers. For this example we might write SQL like:
SELECT firstName, lastName, email
FROM employees;
-- and
SELECT nameFirst, nameLast, contactEmail
FROM customers;
With the two above statements, we now would have to do more external work to make this a single list. Even concepts of Joins and Sub-Queries would not help here as there is not necessarily any relationship between these two tables. Therefore, we need another way to automate the combining of these two resultant sets. This is called Set Operators.
Venn Diagrams and Set Operators (Math Style)
Just to give a little context, many of us took mathematics in high school, middle school, or the equivalent and usually that would cover the topics of Venn Diagrams, Set, and Sequences. Most students often wonder, "Why am I learning this, and when will I ever use this in real life?" Well database is a great example of where we use Venn Diagrams and Set Operators.
For example, in mathematics:
Let A = { 1, 2, 3, 4, 6, 8, 10 }
Let B = { 3, 5, 6, 9, 10 }
A ⋃ B = { 1, 2, 3, 4, 5, 6, 8, 9, 10 } -- union
A ⋂ B = { 3, 6, 10 } -- intersect
A - B = { 1, 2, 4, 8 } -- minus or except
and we may represent these by: 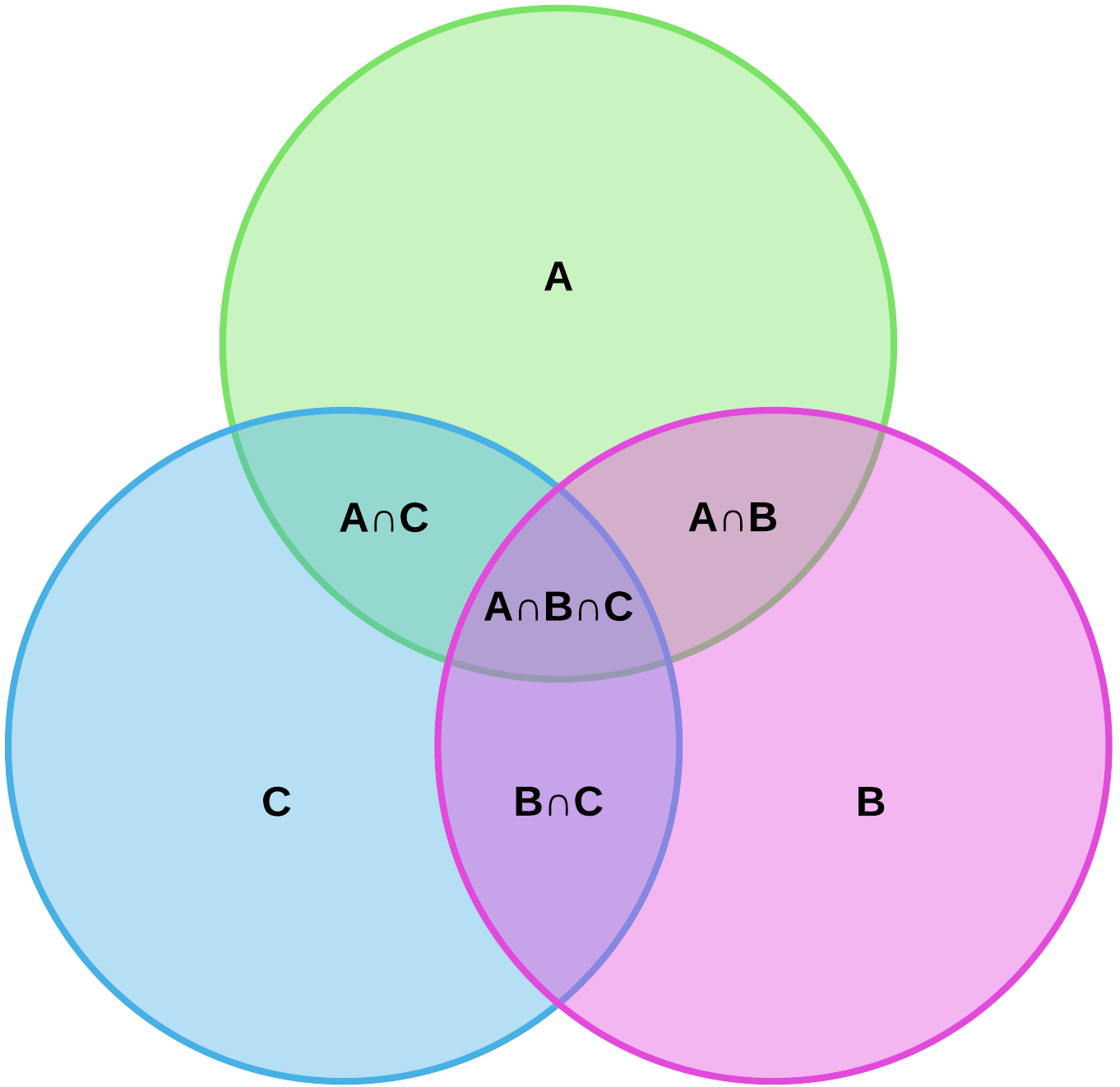
so...
Let A = SELECT * FROM employees; Let B = SELECT * FROM customers; Let C = SELECT * FROM children; -- so we can do: UNION: A ⋃ B INTERSECT: A ⋂ B EXCEPT: A - B
could be extended and visualized using Set Operators and Venn Diagrams
Set Operators
We will look at 4 different Set Operators that are commonly used in SQL that will allow the developer to answer most business questions when combined with other techniques, such as Joins, Sub-Queries, Filtering etc.
The 4 operators we will look at are:
- UNION
- UNION ALL
- INTERSECT
- MINUS or EXCEPT
We will use the following tables for examples on how these set operators work:
| Employees | Customers | |||||
|---|---|---|---|---|---|---|
| firstName | lastName | nameFirst | nameLast | contactEmail | ||
| John | Smith | js@email.com | Julie | Wilson | jw@email.com | |
| Andrew | Jones | aj@email.com | Raj | Patel | rp@email.com | |
| Sarah | Bennet | sb@email.com | John | Smith | js@email.com | |
UNION
UNION is the most used of the set operators, and we will look at how it works. However, it is important to know the difference between UNION and UNION ALL as they have subtle differences that are critical to understand.
So to get a complete list of people, we will need to combine the employees and customers lists into a single list.
SELECT firstName, lastName, email
FROM employees;
-- and
SELECT nameFirst, nameLast, contactEmail
FROM customers;
turns into
-- RED SELECT firstName, lastName, email FROM employees -- note the lack of semi-colon here UNION -- BLUE SELECT nameFirst, nameLast, contactEmail FROM customers; -- All in ONE statement
The results in:
| nameFirst | nameLast | ||
|---|---|---|---|
| Andrew | Jones | aj@email.com | |
| John | Smith | js@email.com | |
| Julie | Wilson | jw@email.com | |
| Raj | Patel | rp@email.com | |
| Sarah | Bennet | sb@email.com |
a few things to note:
- The red rows are those from the first
SELECTportion and the blue rows are from the secondSELECTportion. - The data is sorted in alphabetical order by the first column. - Normally this would be a primary key or other indexed field if they are present.
- Duplicate rows have been eliminated - The person 'John Smith' is only included in the list once, even though he appeared in both tables.
- The column names are the names obtain from the first
SELECTstatement. This means any aliases used in the second statement are irrelevant and not necessary.
Why is the data resorted without an ORDER BY clause?
When you eliminate duplicate records, especially in very large databases, it is much more efficient to sort the data first. To understand this concept, let us look at this in more depth.
If you have 100 records, to determine if a record is a duplicate you would:
- Look at the 2nd record to see if it the same as the first one. If it is eliminate it.
- Look at the 3rd record to see if it is the same as either of the first two, if it is eliminate it
- Look at the 4th record to see if it is the same as any of the first three, if it is eliminate it
- ...
- Look at the 100th record to see if it the same as ANY of the first 99
Obviously as the database gets larger, each new record added means MANY MANY more checks each time, greatly slowing down the database and it's processes. To greatly improve this inefficiency, the data is sorted first.
When you are comparing a record, to determine matches, it is significantly better if they are sorted. When looking at the nth record, we will only need to look at the n-1th record to see if it matches. This means that no matter how many records are in the database (23 or more than a million), each record can be determined to be a match by only looking at ONE previous record.
Just for clarification,
- if not sorted, when reviewing the 100th record, we would have to compare to 99 other records
- if sorted, when reviewing the 100th record, we would only have to compare to 1 other record.
Comparing this if we were reviewing the one millionth record, it is obvious to see the efficiency here.
UNION summary
UNION combines
UNION ALL
UNION ALL works very similar to UNION with a few subtle differences:
- duplicates are NOT eliminated but included as multiple rows
- The data is not re-sorted, the second list of rows will be simply below the first list of rows with each separate list in the order they would naturally be show in.
Using the statement:
SELECT firstName, lastName, email
FROM employees -- note the lack of semi-colon here
UNION ALL
SELECT nameFirst, nameLast, contactEmail
FROM customers;
we will see the resultant set of:
| nameFirst | nameLast | ||
|---|---|---|---|
| Andrew | Jones | aj@email.com | |
| John | Smith | js@email.com | |
| Sarah | Bennet | sb@email.com | |
| John | Smith | js@email.com | |
| Julie | Wilson | jw@email.com | |
| Raj | Patel | rp@email.com |
NOTE: the red rows are from the first SELECT part and the blue rows from the second SELECT part. Note that red and green are not mixed
INTERSECT
Like UNION and UNION ALL, INTERSECT is another set operator that works on multiple incoming resultant sets. INTERSECT specifically finds records that EXACTLY match in both resultant sets. Note: That an exact match means, all column values in both rows are identical. Thus:
SELECT firstName, lastName, email
FROM employees -- note the lack of semi-colon here
INTERSECT
SELECT nameFirst, nameLast, contactEmail
FROM customers;
results in:
| nameFirst | nameLast | ||
|---|---|---|---|
| John | Smith | js@email.com |
The only row that identically appears in both resultant sets.
EXCEPT or MINUS
We use the words EXCEPT or MINUS to describe the same thing where as the only difference is which clause is available in different DBMSs. MINUS is the more common usage and is used in Oracle, MySQL, PostGreSQL, and many others. EXCEPT is the form of the clause that is used in MicroSoft SQL Server.
This clause allows the statement to include all records in the first resultant set, and remove any records that also exist in the second resultant set. Any records in the second resultant set that are not in the first set, are completely ignored.
To see by example:
SELECT firstName, lastName, email
FROM employees -- note the lack of semi-colon here
EXCEPT
SELECT nameFirst, nameLast, contactEmail
FROM customers;
results in:
| nameFirst | nameLast | ||
|---|---|---|---|
| Andrew | Jones | aj@email.com | |
| Sarah | Bennet | sb@email.com |
Note that: no records from the second resultant set are included in any way and that all records from the first resultant set are included except John Smith, whom was removed because that record also exists in the second resultant set.